
Git y los sistemas de control de versiones
Hola a tod@s! Bienvenidos, a un nuevo post de la escuela espai. Hoy hablaremos de los sistemas de control de versiones, en concreto de Git, que es unos de los más famosos y utilizados a día de hoy.
Lo primero que os estaréis preguntando es qué es Git o qué diantres es un sistema de control de versiones. La explicación es muy sencilla. Seguro que alguna vez al entregar un proyecto os han pedido cambios… y cambios, y cambios, y un pequeño retoque, y luego más cambios. Lo sé es una tortura. Así que vuestro proyecto ha acabado pareciéndose a esto:

Es posible que vosotros viváis cómodos con vuestro propio caos y sepáis exactamente qué contiene cada una de esas carpetas. Yo he intentado trabajar así y al final siempre me acabo olvidando de qué era cada cosa.
Aquí es cuando entra Git (o cualquier sistema de control de versiones, tenéis varios en este enlace a wikipedia). Esta herramienta, nos permite almacenar «copias» o versiones de nuestro trabajo que podremos recuperar siempre que queramos. A estas «copias» se las conoce como commits y nos salvarán la vida sin importar los cambios que hayamos hecho o los archivos que hayamos borrado.
¿Es necesario trabajar con Git?
Aprender Git no es complicado. En este mismo artículo aprenderemos 4 pinceladas para utilizar lo básico. Pero ciertamente, como cualquier software, tiene una curva de aprendizaje a la que debemos enfrentarnos. ¿Hasta qué punto es rentable el tiempo que voy a dedicarle al aprendizaje de Git? Esto dependerá de cada uno, de las necesidades y del trabajo que se esté desarrollando.
Si eres un trabajador freelance y estás acostumbrado a trabajar solo, quizá Git no sea tan necesario. Quizá hacer copias manuales de tus archivos te haya funcionado hasta ahora y eso está bien. Pero si realmente estás interesado en evolucionar como profesional te interesa utilizar Git. Trabajar con esta herramienta te permite organizar mejor tus trabajos y evitar riesgos innecesarios. Podrás trabajar sin miedo a perder tu progreso. Así, si te cargas el código podrás recuperar la última versión al instante.
Si trabajas en equipo no hay dudas. Git se vuelve imprescindible. Los miembros del equipo podrán saber qué cambios se han hecho y quién los ha hecho. Podrán solucionar conflictos si dos personas trabajan en el mismo código. Y lo más importante, evitaremos borrar el trabajo realizado por un compañero. Ya veréis que si salís a buscar ofertas de trabajo tanto de front-end como de back-end os pedirán que controléis de Git, ¡así que pongámonos a ello!
Primeros pasos con Git
Empezar a usar esta herramienta es muy sencillo. Sólo tenemos que ir a la página oficial y descargar el programa de forma gratuita. Seleccionamos el sistema operativo que estemos usando, lo descargamos e instalamos (siguiente, siguiente, siguiente…).
Ya estamos listos para usarlo. En este artículo utilizaremos Git a través de la consola de windows. Existe software que nos ayuda a controlar Git, pero creo que aprendiendo a usar unos pocos comandos tendremos suficiente, sin necesidad de instalar programas adicionales.
Para empezar un nuevo repositorio, nos dirigimos a nuestro proyecto mediante la consola y escribimos: git init.
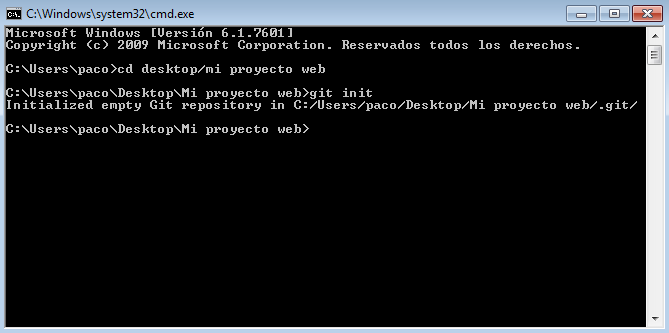
Con esto se nos crea una carpeta oculta (.git), donde el programa almacenará nuestros diferentes commits. Si has guardado algún commit de tu trabajo, puedes hacer cualquier modificación o eliminación de archivos y podrás volver a ese commit cuando quieras. Pero si borras la carpeta .git perderás tu repositorio.
Tu primer commit
Cuando estés satisfescho con tu trabajo y creas que merece la pena guardar una primera versión, puedes realizar tu primer commit. Hacer un commit equivale a marcar un punto en tu repositorio al cual podrás volver cuando quieras. Trabajar con Git es como tener una máquina del tiempo y cada commit es como un portal al cual poder viajar.
Pero para crear un commit, primero tendremos que decirle al repositorio qué archivos quieres salvar. A esto se le llama poner los archivos en el stage. Imagina que cada commit es una fotografía de tu código. Para poder fotografiarlo, Git necesita que saces los archivos al escenario. Cuando tus archivos están listos los sacas al escenario para que les saquen fotos, y esas fotos son las que guardan la información de tu proyecto.
Si introducimos el comando git status, veremos qué modificaciones se han hecho desde el último commit. Podremos saber qué archivos han sido modificados, cuando y por quien.
La primera vez que lanzamos el status, vemos que nos avisa de que aún no estamos haciendo ningún seguimiento.

Así que usaremos git add para añadir los archivos que queramos al stage. Podremos escoger que archivos añadir, pero en este caso no me complicaré la vida y los añadiré todos con git add -A.
Si vuelvo a hacer git status, me aparecerá una lista de la modificación que voy a realizar.

En este caso la modificación es «new file», porque mi repositorio está vacío.
Una vez mis cambios están en el escenario, utilizamos el comando git commit para crear nuestro primer commit. Yo suelo utilizar git commit -m para añadir un mensaje al commit. Es muy importante que cuando creemos un commit le demos un nombre explicativo de los cambios que hemos realizado, para saber qué es lo que hicimos en ese punto de nuestro proyecto.
En mi ejemplo, voy a utilizar este comando: git commit -m «Primera versión de mi proyecto». Así sabré que se trata de mi primer commit.

Como veis, cuando utilizo git status me indica que no tengo nada que guardar, porque no he hecho ningún cambio desde la última modificación. Así mismo, si hago un git log me dará una lista de los commits que he hecho. Si os fijáis se me está dando información sobre el autor y la fecha de los cambios.
Cuando hago cualquier modificación, git status me avisará que tengo archivos modificados. Me dirá cuales de ellos y qué cambios se hicieron. Si queremos más información sobre los cambios, podemos utilizar git diff <nombre del archivo> para obtener los detalles. Por ejemplo voy cambiar el título en el mi archivo index.html.

Como veis, git status me indica que tengo una modificación pendiente, y git diff me dice qué se cambió: en rojo el código anterior y en verde el nuevo.
Por último haré un nuevo commit para salvar estos cambios.

Con git log aparece el nuevo commit al que he llamado «Añado el título al documento index».
Recuperando versiones anteriores
Ahora que ya sabemos guardar versiones de nuestro trabajo, nos interesa aprender a recuperar estas versiones en caso de catástrofe.
Para volver a cualquier commit anterior podemos utilizar el comando git reset –hard [código del commit]. El código de los commits lo encontráis Con esto, volveremos al trabajo tal cual lo teníamos en ese punto, y perderemos todos los commits posteriores.
¿Perderemos los commit? Si hacemos otro git log, veréis como los commits posteriores al commit seleccionado. Pero tranquilos con Git no se pierde nada. Tendremos siempre disponible el comando git reflog que nos hará un listado de todos los commits que han existido para volver a cualquiera de ellos cuando queramos.
Otra forma fácil de recuperar el trabajo es con el comando git checkout –., este comando nos ayudará a dejar el trabajo tal y como se encontraba en el último commit.
Así de fácil. Gracias a Git podremos llevar un control específico sobre nuestros proyectos y trabajar con tranquilidad de una forma ordenada y eficiente.